

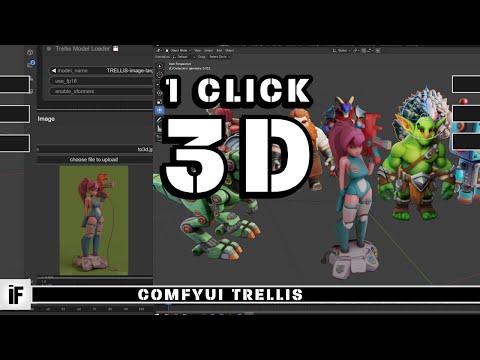







Hey, I have created This Workflow with the help of this You can generates Stories
This Workflow can create a magic story by generating consistent images and videos. Our work mainly has two parts:
Consistent self-attention for character-consistent image generation over long-range sequences. It is hot-pluggable and compatible with all SD1.5 and SDXL-based image diffusion models. For the current implementation, the user needs to provide at least 3 text prompts for the consistent self-attention module. We recommend at least 5 – 6 text prompts for better layout arrangement.
Motion predictor for long-range video generation, which predicts motion between Condition Images in a compressed image semantic space, achieving larger motion prediction.
Key Features:
- Generate consistent images and videos using SD1.5 or SDXL-based diffusion models.
- Use 3-6 text prompts for better character layout and image generation.
- Motion prediction technology to create long-range video sequences from images.
Github: https://github.com/smthemex/ComfyUI_StoryDiffusion?tab=readme-ov-file
