

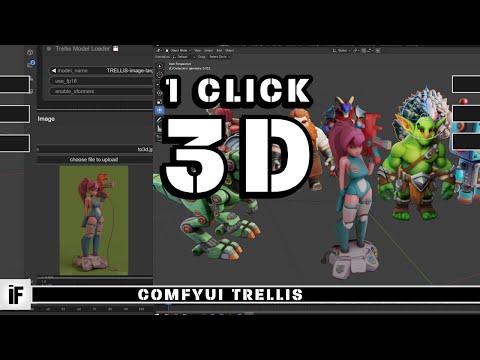






Trying Out Tora Image for AI Video Generation
Here’s the thing—I’ve been testing a bunch of AI video tools lately, and Tora Image caught my attention. It’s not just another text-to-video model. The way it handles motion and longer sequences actually works better than I expected.
What Tora Image Actually Does
So Tora Image is built on this Diffusion Transformer architecture, which sounds complicated but basically means it’s good at keeping video quality consistent, even when you push it beyond the usual 5-second clips. I noticed it handles 204 frames at 720p without falling apart, which is rare for open models.
The key parts that make it different:
- Trajectory Extractor: Figures out how objects should move frame-by-frame
- ST-DiT Module: Manages the spatial and temporal stuff so longer videos don’t get weird
- Motion-Guidance Fuser: Keeps movements smooth instead of robotic
What surprised me was how well it follows both text prompts and image inputs. You can describe something like “a drone flying through a forest” or upload a sketch, and it actually gets the motion right.
Where Tora Image Works Best
I tested it for a few scenarios:
- Short social clips (under 5 seconds): Renders fast, good for quick content
- Longer sequences (10+ seconds): Holds up better than HunyuanVideo when you need more length
- Multi-object motion: If you need two things moving differently in the same scene, it doesn’t blend them into a mess
The motion especially stood out—things like flowing water or swaying trees look way more natural than older models. It’s not perfect, but for an open model, it’s solid.
Anyway, if you want to try it, the weights are up on Hugging Face. Just load it like any other ComfyUI workflow—no special setup needed.

