

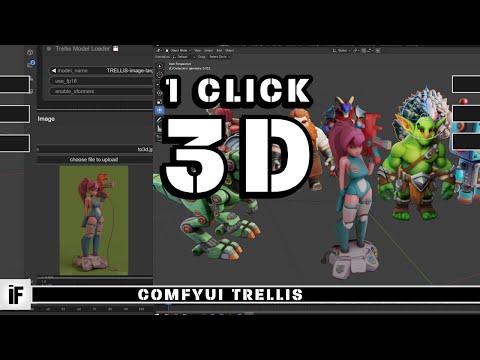






Trying Out the Mochi Workflow for High-Frame Video
Here’s the thing about video generation in ComfyUI—memory usage can sneak up on you fast. I was testing the Mochi workflow and noticed how frame count directly impacts VRAM requirements.
. Turns out you can squeeze under 20GB VRAM if you’re careful with your settings. What caught my attention was the experimental tiled decoder, adapted from CogVideoX’s diffusers implementation.
I didn’t expect this part—the tiled approach actually works. Using a 2×2 grid configuration, I managed to decode a 97-frame sequence without crashing. It’s not perfect (you’ll see some tiling artifacts if you look closely), but for testing longer animations, it gets the job done.
For anyone wanting to try this, grab the models from Kijai’s Hugging Face repo. Just drop the main model into your diffusion_models/mochi folder and the VAE goes in vae/mochi. There’s an auto-download node available now too, though I haven’t tested that path yet—I usually prefer manual installs when trying new workflows.
The real test will be seeing how far we can push this with different tile configurations. I’m curious if anyone in the community has tried larger grids or mixed resolutions. Let me know if you’ve experimented with this approach—would love to compare notes.

